
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- SQL
- 기초통계
- 2021
- 열심히
- 부트캠프
- 딥러닝
- 재미져
- JavaScript
- 자료구조
- 파이썬
- bootcamp
- Codestates
- 매일매일
- leetcode
- Ai
- python
- 꾸준히
- 독서
- 코딩테스트
- yolo
- MYSQL
- 노마드코더
- 선형회귀
- 리뷰
- pandas
- selenium
- 코드스테이츠
- 빅데이터
- 성실히
- 주간보고
- Today
- Total
코딩일기
[Ensseble] Bagging 이해하기 본문

안녕하십니까 다제입니다.
오늘은 Ensseble에서 Bagging에 대해서 이야기를 나누어 볼까합니다.
우리의 목적은 좋은 앙상블 모델을 만들기 위해서
모델의 다양성과 개별적인 모델도 쓸만한 성능을 내는 앙상블을 찾기 위한 과정입니다.
해당 포스팅은
1) 고려대학교 강필성 교수님의 수업자료
2) 코드스테이츠 부트캠프
3) StatQuest 유튜브
등을 참고하여 제가 이해한 내용을 바탕으로 포스팅을 진행하였음을 사전 안내드립니다.
※ 이미지 출처 : github.com/pilsung-kang/Business-Analytics-ITS504-
** 목차 **
-. Bagging의 출연배경
-. Bagging의 개념과 장점
-. Bagging의 단점
** 결론 **
간단하게 Bagging이 무엇인지 알고 싶은 분들을 위해 먼저 결론을 말씀드리고 가겠습니다.
-. Bagging의 정의
* 통계적 분류와 회귀 분석에서 사용되는 기계 학습 알고리즘의 안정성과
* 정확도를 향상시키기 위해 고안된 일종의 앙상블 학습법의 메타 알고리즘입니다.
* 또한 배깅은 분산을 줄이고 과적합을 피하도록 해줍니다.
* Bootstrap Aggregating의 줄임말
-. Bagging의 진행절차
* Bagging(복원추출)을 통해 독립된 다양한 data set을 확보한다.
* Bagging(복원추출) 시, 추출되지 않는 OOB데이터를 검증용으로 사용한다.
* 이렇게 학습된 tree를 Enssemble로 만들어 훈련 시키면 일반화성능이 향상된다.
이에 대한 추가적인 설명이 필요하신 분들께서는 저와 함께 해당 글을 읽어가보시죠
1. Bagging의 출연배경
-. 최신 핸드폰이 나왔을 때는 그 핸드폰이 어찌나 소중하고 단점도 예뻐보일때가 있습니다.
-. Hold out validation을 사용하다가 cross_validation K-fold 방법이 나왔습니다.
-. 딱 최신 핸드폰을 손에 쥐고 있는 듯한 느낌이였겠지요?
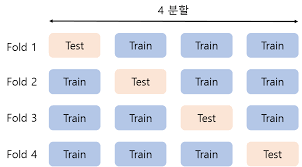
-. 그러나, 사용을 하다보니 이래저래 단점이 보이기 시작합니다.
* 비복원추출에 따른 데이터의 독립성 보장 X -> 모델의 독립성 보장X
* K개의 fold를 만들더라도 검증을 위한 1개의 데이터 fold를 제외하기 때문에 f-1개의 fold를 사용함 -> Data loss
* 데이터가 작을 때는 각각의 fold의 데이터가 작기 때문에 과적합을 이르킬 수 있고 의미가 없어짐
* ( Hold out validation 보다 )시간이 오래걸림
2. Bagging의 개념
과거 선배님들께서는 다시 고민을 해보게 되십니다.
비복원추출로 인한 독립성 결여가 가장 큰 문제가 된다. 이를 어떻게 해결할 수 있을까???
선배님들의 대화를 잠시 들어보겠습니다.
A연구자 : "복원추출을 해보자 !"
B연구자 : ( 눈으로 욕하는 중 )
C연구자 : 자네? 술을 마셨는가? 어처구니 없는 소리를 하는군
D연구자 : 왜 그렇게 제안을 했는가?
A연구자 :
-. 데이터 N가 있다고 가정해봅시다!
-. 그렇다면 이중 1개가 선택되지 않을 확률이 얼라고 생각하는가?
D연구자 :
-. 0.368 이지
C연구자 :
-. D연구자 똑똑하구만!
B연구자 :
-. 아니 설명좀 해보시게 나는 모르겠네!
A연구자 :
Bagging이 Bootstrap Aggregating 줄임말인 것은 알고 있지?
Bootstrap이 복원추출을 의미하네
Bootstrap을 통해 만들어진 1개의 data set의 데이터 수가 n개가 있다고 가정해보자구
그렇다면 이곳에서 어떠한 1개의 샘플이 추출되지 않을 확률이 얼마인가?

그렇다면 이걸 n회 복원추출을 진행했을 때 그 샘플이 추출되지 않았을 확률은 다음과 같겠지?

n을 무한히 크게 했을 때 이 식은 다음과 같다는 거 자네들은 알거라 믿네..!!!

즉 데이터가 충분히 크다고 가정했을 때
Bootstrap을 통해 만들어진 1개의 data set 표본의 63.2% 에 해당하는 샘플을 가지게 되는거야
즉, 우리가 생각하는 것과 다르게 일부 샘플이 추출이 되지 않을 수 있다는 이야기인거지!
B연구자 :
그렇다면 자네의 말은
1) Bootstrap을 통해 추출한 데이터 set으로 모델을 만들어 독립성을 확보하고
2) 추출되지 않는 OOB데이터(36.8%)를 검증용으로 사용하여 일반화 성능을 높이겠다는 말구만
3) 또한 데이터에 구속을 받지 않고 회귀와 분류 모델에 모두 적용할 수 있다니!
4) k-1개의 데이터 loss도 없으니 이보다 좋은 방법이 어디 있겠는가? 오~!
그렇습니다. 위와 같이 bootstrap을 통해 독립적인 모델을 만들고
이를 합쳐서 하나의 앙상블 모델을 만드는 것이 Bagging입니다.
즉, 위 개념을 트리에 적용하여 생각해보면
트리는 구조상 편향이 일정한 범위로 정해질 수 밖에 없습니다.
왜냐하면 가지가 깊이를 조정하고 트리의 수를 조정하여 편향을 줄일 수 있습니다.
또한 앙상블이기 때문에 단일 모델 대비 노이즈에 덜 민감하게 반응합니다.
단, 분산은 늘어날 수 밖에 없습니다.
Bagging의 단점에서 이 부분을 조금 더 살펴보도록 하겠습니다.
3. Bagging의 단점
그렇다면 Bagging은 과연 만능일까요?
정답은 No입니다! 만능이였다면 RandomForest가 나오지 않았겠죠?
위에서도 언급드린 바와 같이 분산은 늘어날 수 밖에 없는 구조 입니다.
분산이 늘어난다는 말은 다르게 생각해보면 훈련데이터에 과적합이 되는 과정으로 생각할 수 있습니다.
이 부분이 RandomForest를 출현 시킨 중요한 요인이 됩니다.
또한, 해석이 어렵고, 단일 모델에 비해 예측 시간이 많이 걸린다는 단점이 있습니다.
물론 feature importance를 통해서 어떤 변수가 중요하게 영향을 주었는지, 트리를 뜯어봐서 어디서
무슨 특성이 있는지 살펴볼 수 있으나, 매우 번거롭습니다.
이러한 해석의 단점을 위해 shap이라던지, PDP라는 라이브러리를 이용하여 해석을 하는 방법에 대해서도
추후 다루도록 하겠습니다.
이상으로 배깅에 대해서 알아보았습니다.
저는 이부분을 공부할 때 어디서 무엇을 배우고 있는지 구조도가 그려지지 않아서
정말 고생을 많이 하였습니다. 부디 개연성을 설명드리는 부분(장점, 단점, 출연배경)을
숙지하셔서 다른 개념들이 들어올 때 혼동되시지 않기를 바랍니다.
오늘도 제 글을 읽어주셔서 감사드립니다.
즐거운 주말 되세요!
'Code > 머신러닝(ML)' 카테고리의 다른 글
| [Ensemble] AdaBoost 이해하기 (0) | 2021.02.20 |
|---|---|
| [Ensseble] RandomForest 이해하기 (0) | 2021.02.20 |
| [Ensseble] 앙상블을 배우는 이유( feat. Bias-Variance Decomposition) (0) | 2021.02.17 |
| 로지스틱 회귀(feat. Logistic regression) (0) | 2021.02.13 |
| [DataScience] Ridge & Rasso regression (feat. L1, L2 Regularization) (4) | 2021.02.13 |



