
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 딥러닝
- 코딩테스트
- 주간보고
- 노마드코더
- Codestates
- bootcamp
- 빅데이터
- 기초통계
- 부트캠프
- 선형회귀
- yolo
- 독서
- pandas
- 자료구조
- SQL
- 꾸준히
- 파이썬
- MYSQL
- Ai
- leetcode
- 2021
- 성실히
- python
- JavaScript
- 열심히
- 매일매일
- selenium
- 재미져
- 리뷰
- 코드스테이츠
- Today
- Total
코딩일기
[Ensemble] AdaBoost 이해하기 본문


안녕하십니까 다제입니다.
지금까지 배웠던 내용에 편향-분산 트레이트오프 관점으로 잠깐 복습해 볼까요?
Bagging - 편향↓ 분산↑ 효과를 줌 ( 즉, 편향↑, 분산↓은 데이터에 적용하면 좋음 )
Boosting - 편향↑ 분산↓ 효과를 줌 ( 즉, 편향↓, 분산↑은 데이터에 적용하면 좋음 )
그럼 Boosting은 어떻게 위와 같은 효과를 주는 살펴보고
그중에서도 AdaBoost가 어떻게 작동하는지에 대해서 알아보도록 하겠습니다.
그러기 위해서는 일단 Bagging과 Boosting의 차이를 알아봐야겠죠?
** 목차 **
1. Bagging vs Boosting
2. AdaBoost의 개념
3. AdaBoost의 장점 & 단점
1. Bagging vs Boosting

-. 공통점
- Bagging과 Boosting은 모두 복원추출을 합니다.
-. 차이점
1) Bagging
전체 데이터을 기준으로 랜덤하게 복원추출을 진행하며 개별적인 모델은 독립적입니다.
이 독립적인 모델을 voting을 통해 합친다.
내가 맞혔던 문제가 중복되어 들어있을 수 있다.
2) Boosting
각각의 모델의 연관성이 있으며 순차적으로 앞 모델이 잘못 맞춘 데이터에 초점을 맞추어 뽑힐 확률을 높여주게 됩니다.
나를 가지고 예측하고 돌아가서 수정하고 또 그걸로 예측하고 또 돌아가서 수정하는 작업이 반복된다.
한 종류의 데이터 set을 가지고 학습 하지만 feature의 가중치가 변동된다.
Weak Model을 사용합니다. 여기서 말하는 Weak Model은 우리가 흔히 알고 있는 stamp Tree를 의미합니다. 즉, stamp Tree는 분류를 딱 한번만 하는 모델로써 depth가 1인 tree라고 생각하시면 됩니다. 이러한 Weak Model의 성능 기준은 Random Guessing과 Decision Tree 사이에 있는 모델들이라고 생각하시면 됩니다. (Random Guessing : 1과 0을 반반씩 섞여있는 데이터에서 한쪽으로 모두 선택하였을 때 맞출 확률이 50%이상 되는 현상을 의미합니다.)
위와 같이 Boosting이 작동이 되는데 편향을 왜 올라갈까? 고민하는 분들을 위해 추가적인 코멘트를 드리자면 곰곰히 고민을 해보시면 Boosting이 틀린 쪽만 바라보고 학습을 진행합니다. 그렇다면 이와 같은 방법으로 학습된 모델도 전체적으로 틀렸던 부분에 쏠려서 모델이 생성되겠지요? 쏠렸다라는 말을 좀 유식하게 바꿔보자면, 한쪽으로 편향되었다라는 말과 같습니다. 즉, Boosting의 경우 편향이 증가할 수 밖에 없는 구조 입니다.
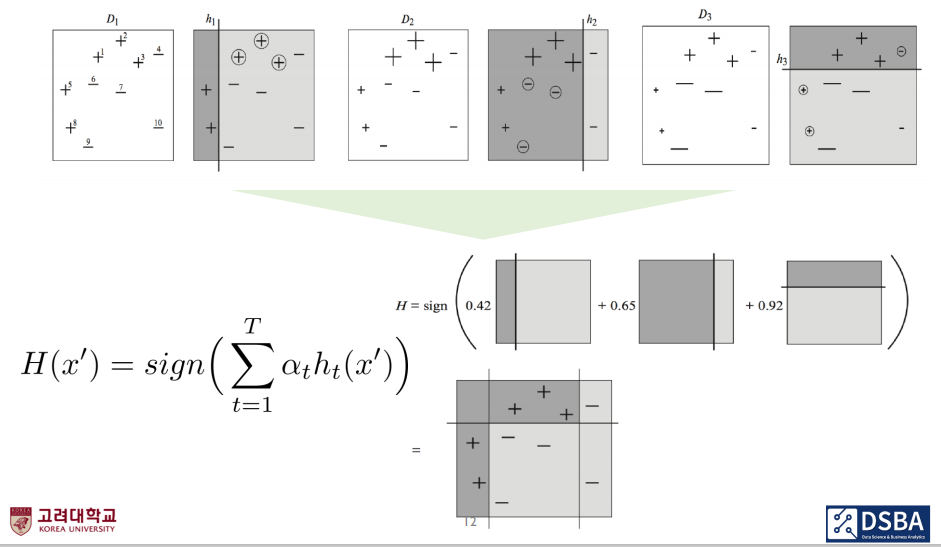
2. AdaBoost의 Algorithm개념

1) 1부터 T까지 반복할 수 있도록 설정합니다.

2) train set을 1부터 N까지 준비하고 y의 예측치는 -1과 1로 수렴하도록 설정을 합니다. ( 로지스틱 - 0, 1수렴 )
* 뒤쪽에서 계산할 때 편하게 해주기 위해서 -1과 1로 설정하는 것입니다.

3) 여기서 왜 D1(i)로 썼는지 이해는되지 않습니다. 우리는 D1(N)으로 놓고 이야기를 진행해보겠습니다.
* 첫번째 데이터 set(D1)에서 N번째가 선택될 확률을 의미합니다.
* 여기서 Define a uniform distribution이라는 말이 적혀 있는데 모델이 맨 처음 분류를 시작할 때는 가중치를 어떻게 줘야하는지 아직 학습하지 못한 상태입니다.
* 이에, 모든 데이터 set에 대해서 동일한 가중치(1/N)을 부여하겠다는 의미입니다.

* 이해를 돕기 위해 statQuest에서 예시 그림을 가져왔습니다.
* 8개의 데이터 set이 있습니다. 각각의 sample에 대한 에러(가중치) 1/8로 두신게 보이시죠?

4) 가설함수 Dt를 사용하여 가설함수 ht를 훈련합니다.

5) ∊t는 현재 학습데이터 D(t)에 대해서 정답 y와 ht(x)가 다를 때의 확률을 의미합니다.
* 우리는 Random Guessing보다 조금 더 성능이 좋은 weak model을 사용하고 있기 때문에 Random Guessing보다
효과가 없는 모델을 만들지 못하도록 체크해주기 위해서 해당 과정이 필요합니다.

6) 만약 ∊t ≥ 0.5 이라면 해당 데이터 셋에 대한 모델 생성을 멈추게 됩니다.

7) 그리고 저희가 그렇게 궁금했던 가중치에 대해서 드디어 계산을 진행합니다.

* 이해를 돕기 위해 위에서 사용했던 statQuest의 설명을 다시 가져와보겠습니다.
* 위에서 Error는 1/8(0.125)이였습니다. 이를 통해 가중치를 계산해보면 아래와 같습니다.
* 가중치(Amount of Say)를 계산해보면 0.97가 됩니다.

* 그렇다면 Error가 1/8(0.125)이고, 가중치(Amount of Say) = 0.97이 됩니다.
8) 이제 가중치를 업데이트 해보겠습니다.

* 이제 구해준 가중치로 Error를 업데이트를 진행합니다.
* 잘못 분류했을 때, 즉, yi = ht(xi)가 같을 때
-. New Sample Weight = (1/8) * e^(-0.97) = (1/8) * 0.38 = 0.05
* 잘못 분류했을 때, 즉, yi = ht(xi)가 같지 않을 때
-. New Sample Weight = (1/8) * e^(0.97) = (1/8) * 2.64 = 0.33
* 여기서 위에서 y예측값이 -1과 1로 수렴하는 이유가 나오게 됩니다.
-. y예측값과 정답 y가 같아지는 경우는 둘다 1이거나 둘다 -1일 경우 입니다.
-. 그렇다면 y예측값 곱하기 y정답은 언제나 1이 되겠지요
-. 그렇다면 거기에 -된 가중치를 곱해지게 되니 위처럼 0.125 -> 0.05로 에러율이 낮아지게 됩니다.
-. y예측값과 정답 y가 다를 경우 y예측값이 -1이면 정답은 1이 되고 또는 그 반대가 되겠지요
-. 그렇다면 y예측값 곱하기 y정답은 언제나 -1이 됩니다.
-. 그렇다면 거기에 -된 가중치를 곱해지게 되니 위처럼 0.125 -> 0.33으로 에러율이 높아지게 됩니다.
9) 위와 같이 선택된 모든 feature에 반복적으로 진행을 해주게 됩니다.
3. AdaBoost의 장점 & 단점
1) 장점
- AdaBoost는 구현하기 쉽습니다.
- AdaBoost는 과적 합되는 경향을 줄일 수 있습니다.
- 약한 분류기의 실수를 반복적으로 수정하고 약한 학습자를 결합하여 정확도를 높입니다.
- RandomForest와 비교하였을 때 대체로 boosting이 속도가 더 빠르고 결과가 더 좋게 나옵니다.
2) 단점
- AdaBoost는 노이즈 데이터 및 이상치에 민감합니다.
- AdaBoost는 XGBoost에 비해 느립니다.
- 우리가 조정해야 하는 hyperparameter의 개수가 늘어납니다.
휴~ 함께 공부하느라 고생하셨습니다.
저는 가중치를 공부할 때 속이 너무 시원하였습니다.
저런 방법으로 가중치가 적용이되다니 신기했고, 재미있었습니다.
혹시 궁금하신 사항이나 오류가 있는 부분은 언제든 피드백 부탁드립니다.
감사합니다.
'Code > 머신러닝(ML)' 카테고리의 다른 글
| The Actual Difference Between Statistics and Machine Learning(feat. statistics study) (0) | 2021.12.02 |
|---|---|
| [Emsseble] GBM 이해하기(ver.1 - Update) (0) | 2021.02.28 |
| [Ensseble] RandomForest 이해하기 (0) | 2021.02.20 |
| [Ensseble] Bagging 이해하기 (0) | 2021.02.19 |
| [Ensseble] 앙상블을 배우는 이유( feat. Bias-Variance Decomposition) (0) | 2021.02.17 |



