
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- python
- selenium
- leetcode
- yolo
- 리뷰
- 코딩테스트
- MYSQL
- 자료구조
- 열심히
- bootcamp
- 코드스테이츠
- 파이썬
- SQL
- 기초통계
- Codestates
- 주간보고
- 성실히
- pandas
- 매일매일
- JavaScript
- Ai
- 독서
- 빅데이터
- 꾸준히
- 2021
- 재미져
- 부트캠프
- 노마드코더
- 딥러닝
- 선형회귀
- Today
- Total
코딩일기
로지스틱 회귀(feat. Logistic regression) 본문
안녕하십니까 다제입니다.
오늘은 Logistic regression에 대해서 알아보고자 합니다.
전부라고는 할 수 없지만, 머신 러닝의 많은 문제는 분류 또는 회귀에 속합니다.
로지스틱 회귀는 회귀이기만 분류 문제를 푸는 알고리즘에 해당됩니다.
또한 분류는 이진분류(Binary Classification)와 다중 클래스 분류(multi class classification)으로 나뉩니다.
로지스틱 회귀는 이진분류에 주로 사용이 됩니다.
여기서 왜 회귀인지 궁금하실텐데요?
로지스틱 회귀(Logistic Regression)는 회귀를 사용하여
데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로
예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는
것으로 분류해주는 지도 학습 알고리즘입니다.
아래 그림을 보실까요?
가운데 선(약 40점)을 기준으로 왼쪽은 0, 오른쪽은 1 이라고 가정할게요

그런데 이러한 분류에는 문제가 있습니다.
0과 1을 분류하는 기준(40점)이 변동이 되면 과연 어떻게 될까요?
분명 분류 스코어가 변동이 될 것입니다.( 즉, 빨간색과 녹색을 잘 분류하지 못하게 됩니다. )
이러한 문제를 해결하기 위해서 위대한 수학자들의 그래프를 아래와 같이 바꾸기로 합니다.
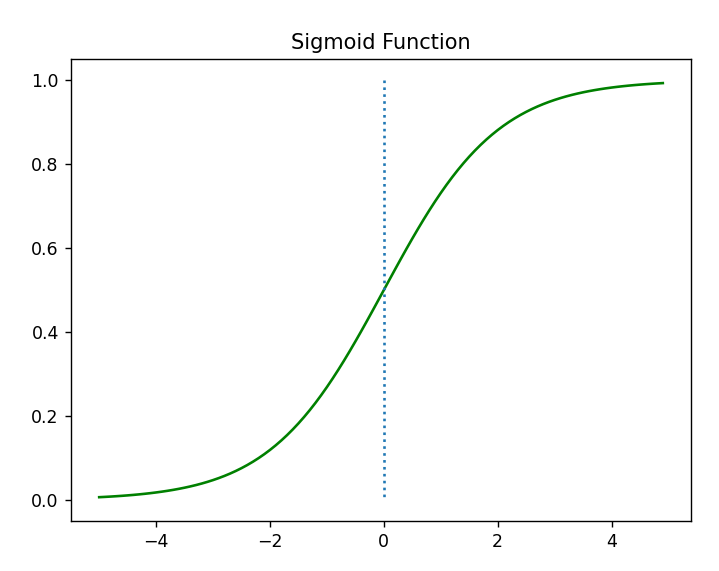
과연 어떻게 하여 이런 그래프가 나오게 되었는지 궁금하시지 않나요?
우리 하나씩 하나씩 풀어가보겠습니다.
위 그래프들은 일반적으로 다항식으로 구성되어 있습니다.
즉, feature가 한 개 이상인 dataset을 가지고 분석을 진행한다는 말입니다.
다항식을 한번 적어보도록 하겠습니다.

오른쪽의 경우 다양한 베타와
y축을 0과 1로 정의하고
x축은 어떠한 사건이 일어날 확률로 정의하고
이를 지수함수( y = e^x라고 합니다.

여기서 x값이 커지면 커질수록 사건이
일어날 확률이 커지게 됩니다.
그런데 우리가 알고 싶은 것은
x값을 넣었을 때 일어날 확률을 알고 싶은 거니까요
y = e^x를 x= 형태로 변형이 필요할거 같네요
e의 x 승을 내릴려면 로그를 취하면 되는거 아시죠?
그래서 수식으로 고치면 x=logey가 됩니다..
( e는 좀 더 작아야하는데.. 작게 그리는 방법을...)
그러면 그래프가 아래와 같이 변형이 되게 됩니다.

이 상태에서 수학적인 처리를 해주면
그래프가 우리가 잘 알고 있는 시그모이드함수로 바뀌게 되는것이죠

여기서 y축은 일어날 확률이 되겠지요
1 = p(x)
0 = 1 - p(x)
여기서 p(x)가 일어날 확률은
odds = p(x) / 1- p(x) 로 정의할 수 있고
이를 odds ratio라고 저희는 부릅니다.
그럼 저희는 이제 x값을 이용하여
어떤 사건이 일어날 확률을 예측할 수 있는
수학적 기반을 다지게 되었습니다.
#-----2021.12.15 추가된 내용-----#


사실 코드로는 몇줄 되지 않습니다만..
이를 이해하기 위한 사전 배경 지식이 상당히 필요했습니다.
회귀들이 모두 그렇더라구요 수학식을 이해는 하였지만
포스팅하는 것은 또 다른 문제였습니다.
앞으로 수학적인 부분과 기하하적인 부분까지 포스팅할 수 있도록
더욱 노력하겠습니다.
'Code > 머신러닝(ML)' 카테고리의 다른 글
| [Ensseble] Bagging 이해하기 (0) | 2021.02.19 |
|---|---|
| [Ensseble] 앙상블을 배우는 이유( feat. Bias-Variance Decomposition) (0) | 2021.02.17 |
| [DataScience] Ridge & Rasso regression (feat. L1, L2 Regularization) (4) | 2021.02.13 |
| [EDA] 무작정 따라하는 EDA3 (0) | 2021.02.07 |
| [DataScience] 선형변환이란? (0) | 2021.02.06 |



