
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- python
- 기초통계
- 노마드코더
- pandas
- 빅데이터
- 파이썬
- 자료구조
- 딥러닝
- 성실히
- 꾸준히
- 코딩테스트
- bootcamp
- yolo
- leetcode
- 2021
- 주간보고
- SQL
- 리뷰
- JavaScript
- 선형회귀
- Ai
- MYSQL
- 재미져
- 열심히
- 매일매일
- 코드스테이츠
- selenium
- 독서
- Codestates
- 부트캠프
- Today
- Total
코딩일기
[DataScience] 머신러닝을 위한 차원축소 ( feat. PCA) 본문

안녕하세요 다제 입니다.
저는 지금 머신러닝을 배우기 위한 사전 통계적, 수학적 개념을 배우고 있는 중입니다.
그 중에서도 선형대수 & 선형회귀 파트를 공부중에 있습니다.
오늘은 선형 회귀분석 중에서도 차원축소에 대해서 알아보도록 하겠습니다.
PCA하는 방법 -> PCA의 component를 구하는 방법 순으로 알아보겠습니다.

우리가 강아지를 알아맞추는 머신러닝을 만든다고 해볼게요
강아지를 나타내는 수 많은 특징들이 feature로 들어갈 수 있습니다.
이 모든 feature을 분석하여 머신러닝을 만든다면 강아지를 알아맞추는데 꽤 정확한 프로그램이 되는게 맞을까요?
실제로 테스트를 진행해보았을 때 일부 feature를 빼고해도 유사하거나 또는 성능이 더 좋게 나오는 경우도 있습니다.
왜냐하면 이 특징들 중 분석을 방해하는 엉터리 데이터들이 있을 수 있기 때문입니다.
feature수가 줄면 -> 데이터를 저장하는 공간이 작아지고, 비용 낮아지니까요!
그렇다면 우리는 적절하게 feature를 줄여서 분석하는게 훨씬 좋겠죠?!
이렇게 차원을 축소하는 것을
Principal Component Analysis (PCA)
라고 하며, 예제 코드를 함께 보면서 설명을 해드릴게요
# 여러분께서 가지고 있는 데이터도 같이 실습을 한번 해보세요~
# select Only number dtypes
# 일단 숫자형 데이터를 선택하여 df1로 만들어주었습니다.
df1 = df.select_dtypes(include=['number'])
# column_name_list
# 정규화된 데이터의 컬럼이름을 붙여주기 위해 컬럼 리스트를 따른 변수에 넣어주자!
col_list= df1.columns.tolist()
# scaling할 메소드 선택
scaler = preprocessing.StandardScaler()
# scaling할 데이터 넘겨주기 및 새로운 데이터 프레임에 저장 및 정규화
# class sklearn.preprocessing에는 fit_transform() 메소드가 있습니다.
# fit의 역할 : train-data를 정규분포로 만들기 위해 평균 𝜇과 표준편차 𝜎를 계산하는 작업
# transform()의 역할 : 정규화 작업
# df1에 대해 평균을 구하고 표준편차를 구하고 정규화를 한번에 하는 하는 코드
# 그리고 위에 따로 빼놓은 col_list를 DataFrame을 넣을 때 같이 넣어주자 !
normalized_data = scaler.fit_transform(df1)
normalized_df = pd.DataFrame(normalized_data, columns=col_list)
normalized_df # 잘 데이터가 변형되었는지 확인하자!
#PCA 메소드를 import해주자!
from sklearn.decomposition import PCA
# 몇 차원까지 축소할 것인지를 여기서 결정해주자
# 일단, 최소로 축소(2개)하는 것을 추천한다. 저는 일부러 4개로 설정해보았습니다.
pca = PCA(n_components=4)
# 우리가 PCA할 데이터를 넣어주고 pc라는 변수에 넣어주자
pc = pca.fit_transform(normalized_df)
# pca를 돌린 데이터를 dataframe으로 만들어주자
pca_df = pd.DataFrame(data=pc, columns = ['PC1', 'PC2', 'PC3', 'PC4'])
# 그리고 카테고리형 데이터인 목표 컬럼을 concat해준다.
pca_df = pd.concat([pca_df, df["Country"]], axis=1)
pca_df.head()
# 이러한 데이터를 이제 시각화보자
plt.figure(figsize= [5,5])
plt.title('PC1-PC2 PCA')
plt.xlabel('PC1_x')
plt.ylabel('PC2_y')
sns.scatterplot("PC1", "PC2", data=pca_df, hue="Country");
실제로 그래프를 그리면 아래와 같은 그래프 유형이 출력이 된다.

그럼 여기서는 문제가 하나 있죠?
다차원의 데이터에서 차원 감소를 시켜주는 것이 PCA의 주목적인 것은 알겠지만,
그렇다면 고차원의 데이터를 어디까지 차원감소 시켜주는 것이 타당할까요?
eigenvalue(고유값)를 계산하여 scree plot을 그려보면 몇 차원까지 감소시켜야하는지 확인 할 수 있다.
(물론 데이터의 공분산 행렬이 full rank임을 가정했을 때이다.)
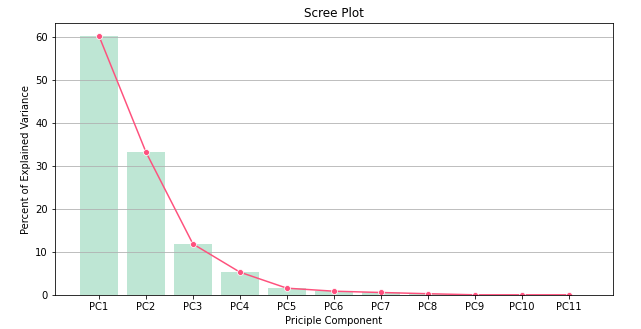
eigenvalue(고유값) 정의
-. 고유값은 component의 분산을 뜻함
eigenvalue(고유값) 해석
-. 고유값 크기를 사용하여 component 수를 결정할 수 있음
-. Scree plot 그래프를 통해 eigenvalue(고유값) 크기를 기반으로 component 수를 결정 가능
def scree_plot(pca):
num_components = len(pca.explained_variance_ratio_)
ind = np.arange(num_components)
vals = pca.explained_variance_ratio_
ax = plt.subplot()
cumvals = np.cumsum(vals)
ax.bar(ind, vals, color = ['#00da75', '#f1c40f', '#ff6f15', '#3498db'])
ax.plot(ind, cumvals, color = '#c0392b')
for i in range(num_components):
ax.annotate(r"%s" % ((str(vals[i]*100)[:3])), (ind[i], vals[i]),
va = "bottom", ha = "center", fontsize = 13)
ax.set_xlabel("PC")
ax.set_ylabel("Variance")
plt.title('Scree plot')
scree_plot(pca)누적
-. 연속적인 component들이 설명하는 표본 변동성의 누적 비율을 뜻함
-. 일반적으로 70~80%이면 무난하다고 판단함 / 90%이상이면 까다로운 조건에 해당함
누적 해석
-. 누적 비율을 사용하면 연속적인 주성분들이 설명하는 전체 분산 양을 평가할 수 있음
-. 아래 코드를 이용하여 누적을 일괄적으로 확인 할 수 있음
# num은 while문을 돌때마다 숫자를 매기기 위한 변수
num = 0
# 누적된 component를 더하기 위한 변수
sum = 0
# component비율이 90%가 넘으면 그만 누적을 하라는 while문
while sum < 90 :
sum = per_var[num] + sum
num += 1
print(f"{num}회:, {sum:.2f}%")
# 혹시 {:.2f}가 궁금하신 분들은 문자열 포맷팅을 확인해보시면 됩니다.
# 해당코드는 소수점 둘째자리까지 표기하라는 의미입니다.
이상 차원축소하는 방법에 대해서 알아보았습니다.
궁금하신 사항이 있으시면 꼭 댓글 부탁드립니다.
감사합니다. ^^
'Code > 머신러닝(ML)' 카테고리의 다른 글
| [DataScience] 제발! 쉽게 가자~ Linear regression야! (2) | 2021.01.28 |
|---|---|
| [DataScience] 머신러닝, k means clustering( feat. just go ) (1) | 2021.01.18 |
| [DataScience] 머신러닝을 위한 미분 ( feat. 평균변화율 -> 순간변화율 ) (6) | 2021.01.12 |
| [Datascience] 머신러닝을 위한 선형대수학 (Feat. 머신러닝 pandas) (0) | 2021.01.11 |
| [Datascience] 선형대수학? 머신러닝? So what? (Feat. AI pandas) (4) | 2021.01.11 |



