
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 딥러닝
- 성실히
- 꾸준히
- 재미져
- 매일매일
- 열심히
- leetcode
- MYSQL
- 부트캠프
- 코딩테스트
- 선형회귀
- 코드스테이츠
- Codestates
- 2021
- 파이썬
- 자료구조
- SQL
- 주간보고
- 빅데이터
- 독서
- 기초통계
- selenium
- pandas
- JavaScript
- 노마드코더
- python
- yolo
- 리뷰
- bootcamp
- Ai
- Today
- Total
코딩일기
[Datascience] 프로그래밍을 위한 기초통계4(feat. 베이즈정리, 베이즈규칙, Bay's) 본문
안녕하십니까 다제입니다.
오늘은 드디어 중심극한정리와 베이즈안 정리에 대해서만 알아보도록 하겠습니다.
범위가 제일 많으나, 할 말이 제일 많은 구간입니다.
구조도를 보면서 바로 시작해보겠습니다.

3-3. 중심극한정리(CLT, Central Limit Theorem)
-. 쉽게 설명하여, 특정 데이터에서 샘플의 평균을 구한 후
-. 그 샘플들로 모집단의 전체 평균을 예측해보는 것이라고 생각하면 쉽습니다.
-. 아래 예제를 바로 보시지요! 코드는 깃허브를 참고해 주세요!
( 링크 : github.com/daje0601/pandas_study )

3-4. 베이즈안 정리
-. 베이즈안 정리를 하기 전, 혼동행렬이라는 개념을 알고 넘어가야 합니다.
-. 혼동행렬이란 ?
- 모델의 성능을 평가할때 사용되는 지표
- 예측값이 실제 관측값을 얼마나 정확히 예측했는지 보여주는 행렬
- 혼동행렬은 민감도와 특이도로 구성됨
잘 와닿지 않으시죠?
최근 코로나19로 진단키트 이야기가 많이 나오는데, 이를 가지고 민감도와 특이도를 설명드리겠습니다.
-. 민감도("TP(r)") : 실제로 감연된 사람을 양성으로 판정하는 확률
* 민감도 높다면 -> 정밀한 검사가능
* 민감도가 낮다면 -> 양성인데 음성으로 결과를 도출하고 코로나19가 막 확산되는 결과를 초래함
이렇게 민감도가 낮아서 발생되는 오류를 위음성, 또는 제 2종 오류라고 합니다.
영어로는 "FN(r)"이라고도 기재합니다.
-. 특이도("FP(r)") : 감염되지 않은 사람을 진단키트가 음성으로 판정하는 확률
* 특이도 높다면 -> 음성으로 잘 판단함
* 특이도가 낮다면 -> 음성인데 양성으로 나타낼 확률 ( 불필요한 치료를 발생시킴 )
이렇게 특이도가 낮아서 발생되는 오류를 위양성, 또는 제 1종 오류라고 합니다.
영어로는 "TN(r)"이라고도 기재합니다.
제가 공부를 해본 결과, 베이즈안은
일단, 베이즈안 이라고 하면 사격형을 그려주세요!
예제1)
약물을 사용한 비율 : 0.5%
위양성(FP : 실제로 약물이 없지만 양성반응을 나타냄) : 1%
양성반응 테스트의 결과가 양성으로 나왔을 경우 실제로 약물이 있을 확률은 어느정도가 될까요?
33.2% = ( 0.99 x 0.005 ) / ( 0.99 x 0.005 + 0.01 x 0.995 )

예제2)
이 사진의 출처는 유튜브에서 참고 youtu.be/Y4ecU7NkiEI 부탁드립니다.
어떤 사람이 나에게 초콜릿을 주었습니다. 오~ 날 좋아하나? 라고 생각할 수 있지요
그런데, 이 피곤한 수학자는 이걸 확률로 계산을 한다고 합니다. 아마 이래서 연애를 못하는게 아닐까 싶은데요
그래도 너무 설명하기 좋은 예여서 공유 드립니다.
여자가 남자를 좋아할 사전확률 : 0.5
좋아하는 사람에게 초콜릿을 줄 확률(TP) : 0.4
좋아하지 않아도 초콜릿을 줄 확률(FP) : 0.3
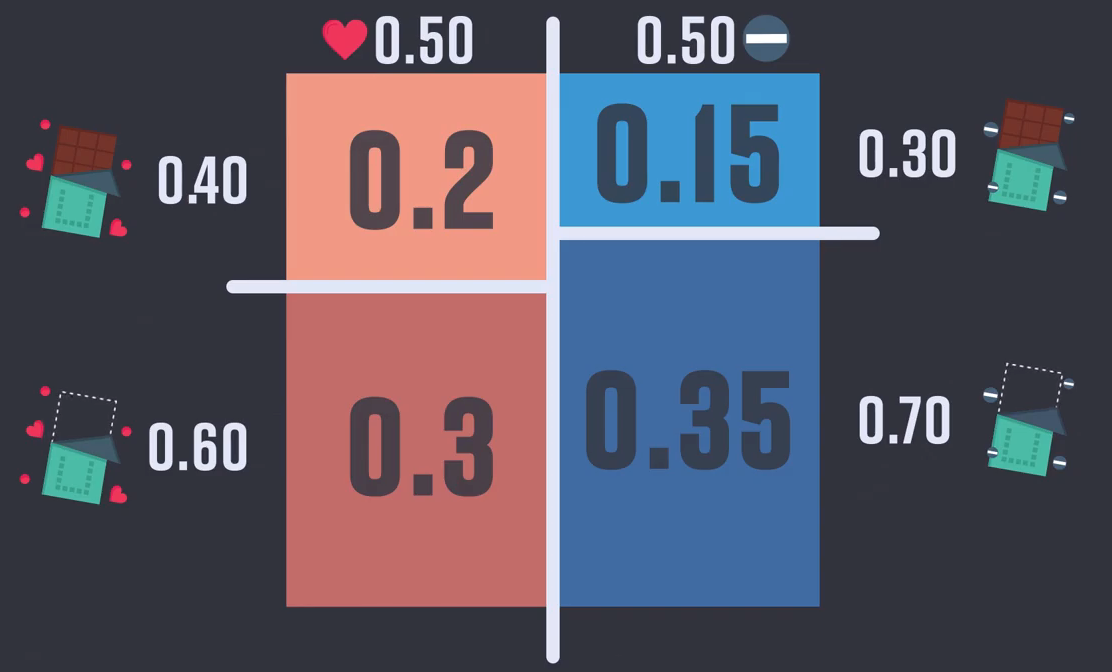
57% = ( 0.50 x 0.40 ) / ( 0.50 x 0.40 + 0.50 x 0.30 )
이를 수학식은 아래와 같습니다. 꼭 공부해보시고 이해가 되실 때까지 봐보시는 걸 추천드립니다.

P(A | B) : A와 B가 동시에 일어날 확률 / B가 일어날 확률
베이즈 정리에 대한 설명과 예제문제는 깃허브에 별도로 올려두었습니다.
꼭 한번정도는 함께 풀어보셨으면 좋겠습니다.
github.com/daje0601/pandas_study/blob/main/pandas_6.ipynb
지금까지 pandas에서 사용되는 기초통계에 대해서 쭉 배워보았습니다.
부트캠프에서 배운 내용을 기준으로 하였기에 통계적 측면에서 부족한 부분이 분명이 있다 생각합니다.
휴~ 정말 하루만에 이 모든 시리즈를 작성하려니 보통이 아니네요..
그래도 완료했다는 점이 뿌뜻하구! 즐겁네요
피드백 주시면 감사히 받도록 하겠습니다.
시리즈로 업로드한 기초통계를 봐주셔서 너무 감사드립니다.
'Code > 머신러닝(ML)' 카테고리의 다른 글
| [Datascience] 머신러닝을 위한 선형대수학 (Feat. 머신러닝 pandas) (0) | 2021.01.11 |
|---|---|
| [Datascience] 선형대수학? 머신러닝? So what? (Feat. AI pandas) (4) | 2021.01.11 |
| [Datascience] 프로그래밍을 위한 기초통계3(feat. anova, 베이즈정리리 사전공부) (0) | 2021.01.10 |
| [Datascience] 프로그래밍을 위한 기초통계2(feat. Univariate analysis, skewness) (0) | 2021.01.10 |
| [Datascience] 프로그래밍을 위한 기초통계1(feat. pandas, ttest) (0) | 2021.01.10 |



