
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 코드스테이츠
- 딥러닝
- leetcode
- 파이썬
- 열심히
- 주간보고
- JavaScript
- 빅데이터
- 코딩테스트
- 매일매일
- 독서
- 노마드코더
- 2021
- python
- Codestates
- 선형회귀
- yolo
- 성실히
- 꾸준히
- Ai
- 재미져
- 자료구조
- SQL
- 부트캠프
- pandas
- bootcamp
- 기초통계
- 리뷰
- MYSQL
- selenium
- Today
- Total
코딩일기
Efficient Streaming Language Models with Attention Sinks(feat. Attention Sinks, text of infinite length without fine-tuning) 본문
Efficient Streaming Language Models with Attention Sinks(feat. Attention Sinks, text of infinite length without fine-tuning)
daje 2023. 10. 18. 17:15Attention Sinks로 더 많이 소개되고 있는 논문 : Efficient Streaming Language Models with Attention Sinks(feat. text of infinite length without fine-tuning)에 대해서 오늘은 한번 알아보고자 해요. 어떤 문제를 해결하고 싶었고, 어떻게 아이디어 발견하였고, 수식과 코드까지 어떻게 연결되었는지 한 큐에 설명드릴테니 잘 따라오셔요!
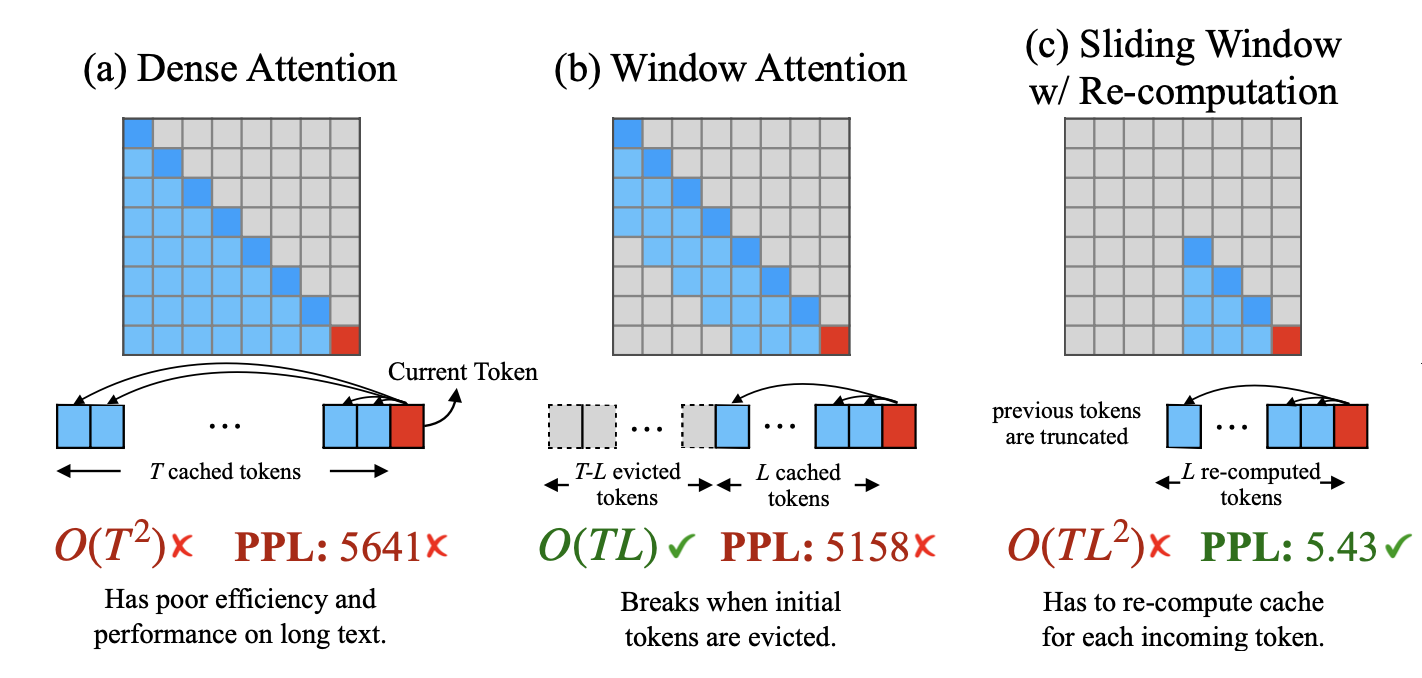
기존 문제점
mit-han-lab의 영상 중 왼쪽 영상처럼 KV Cache보다 긴 문장을 생성하다보면, 모델이 튀어 이상한 문장을 생성하는 것을 발견할 수 있습니다. 원 저자는 이 문제를 논문에서 아래와 같이 말하고 있습니다. (여기서 한 가지 오해할 수 있는 사실이 엄청 긴 입력문장을 넣는 다는 것이 아니고, 영상처럼 모델이 무한한 생성을 하는 것을 기준으로 생각을 하셔야합니다.)
Window attention, where only the most recent KVs are cached, is a natural approach — but we show that it fails when the text length surpasses the cache size.
It is very challenging for LLM to generalize to longer sequence lengths than they have been pretrained Llama-2.
The reason is that LLms are constrained by the attention window during pre-training.
The acceptable sequence length remains finite, which doesn't allow persistent deployments.
StreamingLLM 나온 배경과 아이디어
Dense Attention, Window Attention, Sliding Window with Re-computation 등 다양한 방법으로 연구를 하였지만, 이러한 문제를 해결하지 못했습니다.
그러던 중 저자들은 특이한 점을 하나 발견하게 됩니다.
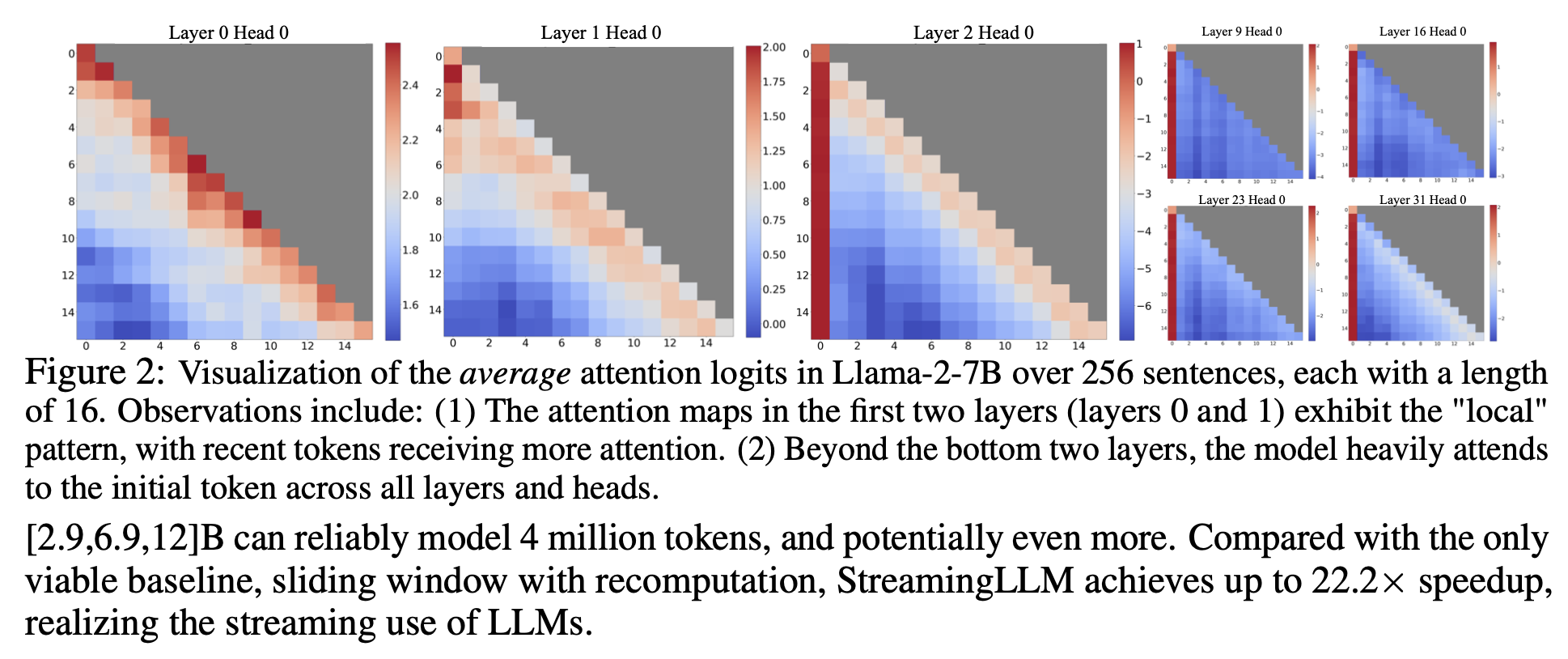
Layer2의 initial token에 score가 몰려있는 것을 관찰하게 됩니다. 그리고 이러한 이유를 softmax 때문이라고 생각한다고 이야기합니다. softmax과 하면 가장 중요한 토큰을 찾고, 모든 토큰의 합을 1로 만들어야 합니다. token별 중요도를 계산하게 되는데, 진짜 중요한 것을 찾고나면 나머지 점수들을 어디에 배정해야할지 모른다는 것이죠. 그래서 현재 토큰과 의미적으로는 큰 관계는 없지만, 그래도 initial token에 중요도를 부여하게 된다고 저자들은 이야기 하고 있습니다.
To understand the failure of window attention, we find an interesting pehnomenon of autoregressive LLMs: a superrisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task.
We attribute the reason to the Softmax operation, which requires attnetion scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one.
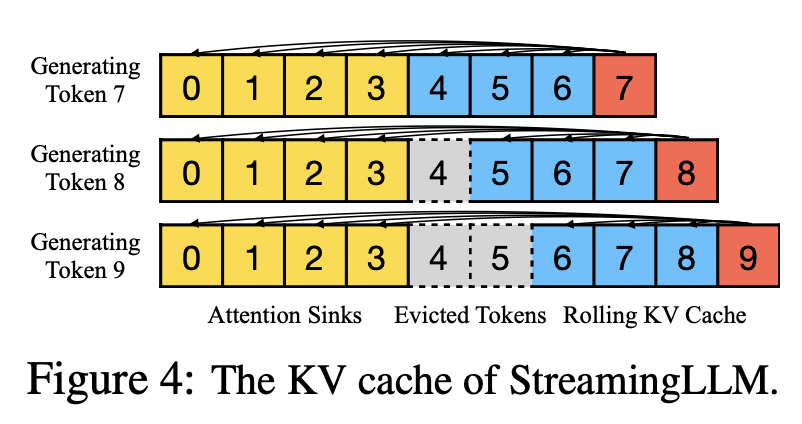
저자들은 이러한 insight를 활용하여 StreamingLLM을 제안하게 됩니다. 이것은 단순하고 효율적인 프레임워크라고 그들은 이야기하고 있습니다. 즉, softmax를 계산할 때, 수식을 조금 변경하여 최초 4개의 initial token을 계속 가지고 가면서 생성을 이어갑니다.
이를 수식적으로도 함께 살펴보겠습니다.

이처럼 분모에 시작 토큰을 고정을 가져가게 되므로, 문맥의 전반적인 흐름을 놓치지 않고, streaming으로 text를 생성할 수 있는 프레임워크를 제안하게 됩니다. 논문에서는 아래와 같이 언급하고 있습니다.
Based on the above insights, we propose StreamingLLM, a simlpe and efficient framework that enalbles LLMs trained with a finite attention winodw to work on text of infinite length without fine-tuning.
Therefore, StreamingLLM simply keeps the attention sink tokens'KV (with just 4 initial tokens sufficing) together with the sliding window's KV to anchor the attention computation and stabilize the model's performance.
이러한 수식 코드로는 어떻게 반영되고 있는지에 대해서 한번 살펴보도록 하겠습니다.
이를 코드로 구현하는 방법은 크게 두가지가 있습니다. 원 저자가 작성한 방법과 허깅페이스로 구현한 방법이 있습니다.
하나씩 살펴보겠습니다.
코드구현
1) 원자자의 방식(https://github.com/mit-han-lab/streaming-llm)
여기서 살펴보아야 할 점은 torch.cat 부분입니다. k_sclice를 통해 0부터 4번째 토큰을 항상 가져가는 것을 볼 수 있습니다. 이게 바로 앞에서 보았던 4개의 token을 계속 가져가며 생성하는 것입니다.
# 코드 경로 : https://github.com/mit-han-lab/streaming-llm/blob/main/streaming_llm/kv_cache.py
class StartRecentKVCache:
def __init__(
self,
start_size=4,
recent_size=512,
k_seq_dim=2,
v_seq_dim=2,
):
print(f"StartRecentKVCache: {start_size}, {recent_size}")
self.start_size = start_size
self.recent_size = recent_size
self.cache_size = start_size + recent_size
self.k_seq_dim = k_seq_dim
self.v_seq_dim = v_seq_dim
self.k_slice = DIM_TO_SLICE[k_seq_dim]
self.v_slice = DIM_TO_SLICE[v_seq_dim]
def __call__(self, past_key_values):
if past_key_values is None:
return None
seq_len = past_key_values[0][0].size(self.k_seq_dim)
if seq_len <= self.cache_size:
return past_key_values
return [
[
torch.cat(
[
self.k_slice(k, 0, self.start_size),
self.k_slice(k, seq_len - self.recent_size, seq_len),
],
dim=self.k_seq_dim,
),
torch.cat(
[
self.v_slice(v, 0, self.start_size),
self.v_slice(v, seq_len - self.recent_size, seq_len),
],
dim=self.v_seq_dim,
),
]
for k, v in past_key_values
]
2) huggingface 방식(https://github.com/tomaarsen/attention_sinks/tree/main)
어떤 분이 친절하게 pip로 설치할 수 있도록 코드를 만들어주셨어요! 이 글을 그 분이 직접 보시진 않겠지만, 그래도 고맙습니다!
여기서는 코드를 직접 구현하지 않고, huggingface에 구현된 streamer라는 class를 이용하여 구현하셨더라구요.
streamer도 위 코드와 작동하는 방식은 비슷합니다. 단, 여기서는 min_new_token과 max_new_token을 파라미터 값을 넣어주어야합니다. 1번처럼 무한하게 생성을 하는 것이 아니라 max_new_token까지만 생성을 진행하게 됩니다.
import torch
from transformers import AutoTokenizer, TextStreamer, GenerationConfig
from attention_sinks import AutoModelForCausalLM
# model_id = "meta-llama/Llama-2-7b-hf"
# model_id = "mistralai/Mistral-7B-v0.1"
model_id = "mosaicml/mpt-7b"
# model_id = "tiiuae/falcon-7b"
# model_id = "EleutherAI/pythia-6.9b-deduped"
# Note: instruct or chat models also work.
# Load the chosen model and corresponding tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_id,
# for efficiency:
device_map="auto",
torch_dtype=torch.float16,
# `attention_sinks`-specific arguments:
attention_sink_size=4,
attention_sink_window_size=252, # <- Low for the sake of faster generation
)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
# Our input text
text = "Vaswani et al. (2017) introduced the Transformers"
# Encode the text
input_ids = tokenizer.encode(text, return_tensors="pt").to(model.device)
with torch.no_grad():
# A TextStreamer prints tokens as they're being generated
streamer = TextStreamer(tokenizer)
generated_tokens = model.generate(
input_ids,
generation_config=GenerationConfig(
# use_cache=True is required, the rest can be changed up.
use_cache=True,
min_new_tokens=100_000,
max_new_tokens=1_000_000,
penalty_alpha=0.6,
top_k=5,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
),
streamer=streamer,
)
# Decode the final generated text
output_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
간단한 방식으로 이렇게 LLM을 바꿀 수 있다는 점에서 놀라웠던 논문입니다.
감사합니다.
'Code > 딥러닝(NL)' 카테고리의 다른 글
| embedchain, RAG DB 쉽게 업데이트 하는 방법(feat. 유튜브 영상하고도 대화가 가능하다고? 거기다가 배포도 쉽다고?) (0) | 2023.12.15 |
|---|---|
| Gemini(제미나이), 늦기 전에 알아보세요(feat. Google multi-modal) (2) | 2023.12.08 |
| Gradient Accumulation과 Gradient CheckPointing을 왜 쓸까?(feat. LLM) (1) | 2023.10.16 |
| git release git에 대용량 파일을 업로드하는 방법 (0) | 2023.08.24 |
| KL divergence Loss (feat. RAG, Facebook, Loss) (0) | 2022.12.01 |



