
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 주간보고
- Ai
- SQL
- 자료구조
- bootcamp
- 성실히
- selenium
- 꾸준히
- 재미져
- 매일매일
- pandas
- 열심히
- Codestates
- 딥러닝
- 2021
- python
- 파이썬
- 코딩테스트
- leetcode
- yolo
- MYSQL
- 코드스테이츠
- 선형회귀
- 독서
- 기초통계
- 노마드코더
- 빅데이터
- JavaScript
- 리뷰
- 부트캠프
- Today
- Total
코딩일기
RAG: Retrieval-augmented Generation for Knowledge-intensive Task(feat. blenderbot, facebook) 본문
RAG: Retrieval-augmented Generation for Knowledge-intensive Task(feat. blenderbot, facebook)
daje 2022. 12. 5. 21:57
안녕하십니까 다제입니다.
오늘은 RAG, Retrieval-augmented Knowledge-intensive Task라는 논문을 알아보도록 하겠습니다.
제목에서 알 수 있는 Knowledge-intensive Task를 해결하기 위해 검색된 내용(retrieval)을 조합(augmented)하여 생성하는 모델이다 라고 볼 수 있습니다. 해당 논문은 2021년 facebook에서 발표한 논문입니다. 이 논문을 보게 된 이유는 RAG는 facebook Blenderbot의 backbone이 되기 때문에 이를 이해하는 것이 블랜더봇에 대한 이해를 높여줄거라고 생각하여 깊게 논문을 리뷰하게 되었습니다. 이 포스팅을 이해하기 위해서는
1. ODQA(open-domain QA)와 Know-Intensive task의 이해가 필요하며,
2. retrieval를 담당하는 DPR 모델에 대한 배경지식이 있어야 이해하실 수 있습니다.
왜냐하면, RAG라는 논문은 ODQA와 Know-Intensive task를 연결해주는 가교 역할을 하기 때문입니다.
본 글을 아래 목차로 진행하겠습니다.
- Introduce ODQA & Know-Intensive Task
- Follow-up ODQA Papers
- Review RAG paper
Introduce ODQA & Know-Intensive Task (ODQA & Know-Intensive Task 소개)
ODQA와 Know-Intensive Task가 무엇인지 모르는 분들을 위해 잠깐 개념을 잡고 넘어가겠습니다.
ODQA란, 특정한 도메인에 국한을 두지 않고, 질문(Q, Question)이 들어왔을 때 DB에서 관련된 문서(doc or passage)를 찾고, 찾은 문서에서 정답(A, Answer)을 찾아주는 2 단계로 구성되어 있습니다. 1)DB에서 관련된 문서를 찾아주는 모델과 2)찾은 문서에서 정답을 찾는 모델 2개가 필요합니다. 여기서 중요한 것은 정답은 연속된 토큰(Continuous Span)으로 정답이 존재하는 경우가 많다는 것이다. 즉, 이 말은 일반적인 ODQA task에서는 연속된 토큰으로 답이 존재하지 않을 경우, 성능이 떨어질 수 있고, Task를 타는 경우가 있습니다.
Know-intensive task란, AI 연구원이 광범위한 작업을 수행하기 위해 실제 지식을 더 잘 활용할 수 있는 모델을 구축하는 데 도움이 되는 새로운 통합 벤치마크입니다. Know-intensive task는 크게 fact-checking, open-domain question answering, slot filling, entity linking, and dialog generation으로 구성되어 있으며, 보다 자세한 내용은 facebook의 KILT를 참고해보세요.
Follow-up ODQA Papers (ODQA 논문 흐름 파악)
이제 대략적으로 ODQA와 Know-Intensive Task가 무엇인지 알았으니, ODQA 관련 논문의 흐름을 살펴볼까 합니다.
ODQA의 논문의 흐름을 보면서, 각 논문이 가지는 의의와 목적을 살펴보고 RAG가 왜 중요한지 체감해보도록 하겠습니다.
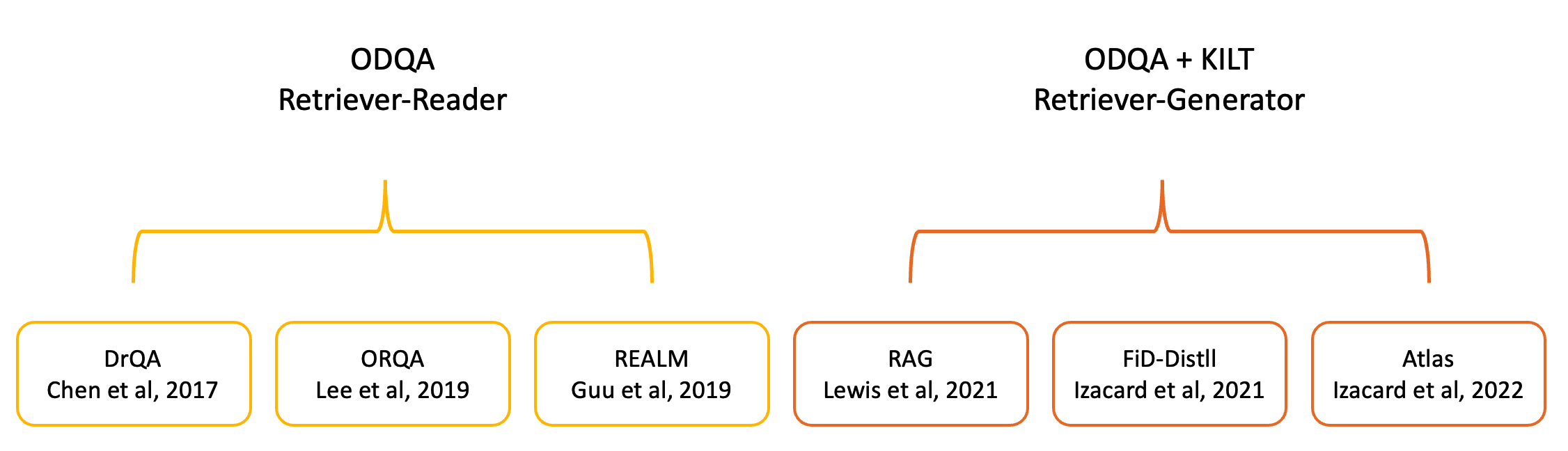
사실 ODQA의 역사는 그리 길지 않습니다.
각 논문별로 특징을 간략하게 조사해왔습니다. 함께 살펴보시죠~
DrQA : OpenDomain-QA를 제안한 논문
-. 모델의 weight에 이 세상 모든 정보를 담는 것은 논리적으로 말이 되지 않아!
-. 질문에 대한 정답을 외부 지식 데이터 베이스에서 찾아오자
OrQA : retriever 학습에 필요한 신호를 처음으로 제안한 논문
-. 정답을 찾긴 찾는데, 잘 못찾네.. 우리 그럼 Retriever를 훈련시켜보자!
REALM : 처음으로 ODQA Framework 제안한 논문
-. Retriever만 학습시키는게 아니라 Reader도 함께 End-to-End로 학습 시켜보면 좋을거 같아!
RAG : ODQA와 Know-Intensive task를 연결한 논문
-. Retriever만 학습시키는게 아니라 Generator도 함께 End-to-End로 학습 시켜는데 생성까지 하면 더 좋을거 같아
-. 즉, 찾은 정보를 활용하여 말을 하는 영역으로 넘어오게 됨
FiD-Distill
-. 수 백개의 문서를 동시에 처리할 수 있도록 RAG에 FiD를 사용하는데, 너무 무겁잖아. 경량화를 해보자
Atlas
-. 공부중..
Open-Domain QA 어떤 흐름으로 진행되는지 간략하게 살펴보았는데, 대략적으로 어떤 흐름을 가지고 발전했는지 느낌이 오시나요? 이제는 본격적으로 RAG논문에 대해서 리뷰를 진행해보도록 하겠습니다.
RAG paper review
1. Introduction
-. 기존의 모델들은 Implicit parametric knowledge으로 제작하다보니 확장성과 저장 정보 수정을 할 수 없다라고 이야기하고 있습니다. 또한, 모델은 그럴듯한 오답인 생성하는 hallucination 현상이 일어난다고 이야기합니다. 이러한 단점 때문에 non-parametric memories를 결합한 모델이 나왔습니다.
-. 여기서 모르는 용어가 있을실거 같아서 잠깐 정리를 해보자면, Implicit parametric memories는 모델 파라미터에 저장된 정보를 이야기하며, Explicit non-parametric memories는 모델 외부에 있는 정보(일반적으로 DB)를 이야기합니다. Implicit parametric memories과 Explicit non-parametric memories를 결합하여 만든 대표적인 모델이 REALM입니다.
-. 저자들은 REALM의 연장선으로 parametric memories과 non-parametric memories를 결합한 Generation Model을 만들었고, 이는 RAG(Retrieval-augmented Generation)라고 부르며, parametric memories는 seq2seq transformer를 사용하였고, non-parametric memories로는 dense vector index of Wikipedia를 사용했다고 합니다. 이렇게 만든 RAG 모델은 QA의 open Natural Questions, WebQuestions and CuratedTrec에서 SOTA를 달성하였고, intensive-task(fact verification)에서도 SOTA를 달성하였다고 합니다.
2. Methods
-. RAG의 작동 방식은 input sequence $x$가 들어왔을 때 text document(non-parametric memories) 에서 관련된 documents $z$를 찾고 이를 활용하여 target sequence $y$를 생성합니다.

-. rag는 Retriever와 Generator라는 2개의 요소로 구성되어 있습니다.
-. 앞서 언급 드렸듯, Retriever에서는 input sequence $x$가 들어왔을 때 text document(non-parametric memories) 에서 관련된 documents $z$를 찾는 역할을 담당합니다.
-. Generator는 input sequence $x$와 documents $z$ 그리고 1부터 i-1까지 token(y)가 주어졌을 때 $y_{i}$가 나올 확률을 계산하며 생성을 진행하게 됩니다.
-. retriever와 Generator를 end-to-end로 훈련시키기 위해, 검색된 $z$를 latent variable로 다루었습니다.
-. 또한, text generation을 위해 2가지 모델을 제안하였는데
1) 첫 번째가 RAG-Sequence이고, RAG-Sequence는 동일한 문서를 사용하여 다음에 올 토큰을 예측합니다.
2) 두번째가 RAG-Token이며, RAG-Token는 여러 문서를 이용하여 다음에 올 토큰을 예측하게 됩니다.
좀 더 깊이 들어가 보겠습니다.
2.1 Models
먼저, RAG-Sequence에 대해서 조금 더 깊게 알아보도록 하겠습니다.
RAG-Sequence는 동일한 문서를 사용하여 다음에 올 토큰을 예측한다고 말씀 드렸습니다.
이를 조금 더 풀어서 설명을 드리겠습니다. 우리는 retriever를 사용하여 여러 개의 doc를 가져오게 됩니다. 그 중에서 한 개의 doc를 일단 선택하고 text generation을 진행하게 됩니다. 만약 5개의 doc가 있었다고 하면 5개의 answer가 생성이 되겠지요. RAG-Sequence에서는 여러 개의 doc를 검색하더라도 한 개의 doc에서 한 개의 answer를 생성하기 때문에 single latent variable를 이용한다고 볼 수 있습니다. 이를 수식으로 쓰면 이렇게 쓸 수 있습니다.

위 식은 이렇게 나누어서 생각할 수 있습니다.
$ p_{η} (z|x)$는 retriever에 입력 x가 들어갔을 때 z가 나올 확률입니다.
$ p_{\theta}(y|x,z)$는 x와 z가 주어졌을 때 정답 y가 나올 확률입니다.
이 두 식을 곱하므로써 두개의 다른 모델에서 각각 개별적으로 일어나는 task들을 end-to-end로 학습 할 수 있게 됩니다.
이제는 RAG-Token에 대해서 알아보도록 하겠습니다.
RAG-Token 모델에서는 Generator가 각 대상 토큰에 대해 다른 latent variable documents에서 token을 선택하여 Answer를 생성할 수 있도록 합니다.

2.2 Retriever: DPR
먼저 DPR이란, Training 단계에서는 연관된 question-passage끼리 가까운 공간에 위치하는 vector space를 구축 한 후 FAISS 형식으로 저장하여 새로운 질문이 입력으로 들어왔을 때 연관된 passage를 빠르게 검색하는 방법입니다.
FAISS는 시맨틱 검색을 이용하는 벡터 검색 라이브러리로써 기존에 사용되는 키워드 매칭이 아닌 문장의 의미에 초점을 맞춘 정보 검색 시스템으로 이해하시면 될 거 같습니다. RAG는 Retriever로는 DPR를 사용하였으며, DPR은 bi-encoder architecture를 사용하였습니다. 말 그대로 2개의 encoder를 사용하였다는 건데요, encoder로는 Bert_base모델을 사용하였으며, 하나는 query encoder로 사용하고 하나는 document encoder로 사용합니다. 여기서 중요한 것은 input $x$가 들어왔을 때 모든 Documents를 인덱싱와의 내적을 구하여 내적값이 최고로 높은 document을 찾아가는 방법을 MIPS (Maxium Inner Product Search)라고 합니다. 매번 인덱싱하여 유사도가 높은 문서를 top-k를 찾는 것은 너무 비효율적이기 때문에 모든 Documents에 대해 미리 indexing을 진행해 둡니다. 이런 구조를 만들기 위해 bi-encoder를 사용하게 됩니다. 이 해당 DPR retriever는 TriviaQA question과 Natural Question 으로 미리 fine-tuning 되어 있는 모델입니다. 앞에서 언급한 Non-parametric memory가 이 모든 Document의 index를 언급한 것입니다.
그럼 정리 해보겠습니다.

- Retriever :
- DB(Wiki) 등에서 관련된 정보를 검색해주는 모델 ( 방대한 정보량을 줄여주는 역할 )
- Encoder 구조 ( BERT, BM25, Faiss 등이 사용될 수 있음 )
- $Score_{retriever}(p,q) = Encoder_{p}(p) · Encoder_{q}(q)$
- passage와 question Encoder가 존재하며 내적값으로 Score를 구하게 됨
- Answer 산출 시, Passage의 weight로 작용하게 됨
2.3 Generator:BART
해당 논문에서는 Generator로 BART-large 모델을 사용하였고 각각의 generator 방식에 따른 구조는 아래와 같습니다.

논문에서는 RAG-Sequence방식이 생성을 할 때 검색된 모든 문서를 참고하면서 생성하지 않기 때문에 일부 생성되지 않는 문장들이 있을 수 있다고 합니다. 그래서 추가적으로 forward를 돌려서 생성되지 않는 문장을 생성할 수 있도록 추가적인 연산을 진행하게 되는데 이를 논문에서는 철저한 디코딩 방식(Thorough Decoding)이라고 언급되어 있습니다. 또한, 논문에서는 매번 이렇게 추가적인 연산을 들여가며 문장을 생성할 수 없기 때문에 발견되지 않는 확률 값들은 0으로 처리하여 연산량을 줄인다고 언급하고 있습니다. 이러한 문제점 때문에 RAG-Token 생성방식이 나오게 되었습니다.

2.4 Training
이제 Training에 대해서 알아보도록 하겠습니다.
논문에서는 retriever와 generator components를 jointly하여 direct supervision 없이 훈련을 하였다고 합니다.
과연 어떻게 query encoder의 가중치를 업데이트 할 수 있었을까? 매우 궁금해하셨을텐데요.
이는 huggingface의 loss 부분 코드를 살펴보아야 조금 이해를 할 수 있습니다. 논문에는 query encoder 가중치 업데이트에 대한 별다른 언급이 없습니다(링크)
이곳에 가서 보시면, RagTokenGeneration class에서 get_nll이라는 loss 함수가 있는데, 이를 천천히 살펴보시면 document score loss에 들어가는 것을 볼 수 있습니다. 들어갈 때 log_softmax값을 취한 후 -(마이너스)가 붙어서 들어가게 됩니다. 이는 encoder가 유사도가 높은 document를 뽑으면 잘할 것이니 -값을 주어 더 많은 loss가 감소하는 원리로 코드가 구성되어 있으니 꼭 코드를 보시면서 참고해보시면 좋을 거 같습니다.
앞에서도 언급 드렸다시피 document encoder(BERT)는 freeze 시켜놓은 상태로 query encoder와 bart만 fine-tuning 하게 됩니다. 이러한 이유를 논문에서 짧게 언급하고 있는데요. 같이 훈련을 시켜봐도 좋은 성능을 관찰 할 수 없었다 라고 이야기하고 있습니다.
실험과 결과 부분은 제가 업로드한 유튜브 영상을 참고해주시면 감사드리겠습니다.
이상 RAG에 대해서 알아보았습니다.
긴 글 읽어주셔서 감사드립니다.

