
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Ai
- 독서
- 부트캠프
- 선형회귀
- Codestates
- JavaScript
- 재미져
- 빅데이터
- pandas
- yolo
- 주간보고
- 코드스테이츠
- 노마드코더
- 기초통계
- MYSQL
- 파이썬
- 매일매일
- 자료구조
- 딥러닝
- 2021
- SQL
- bootcamp
- 꾸준히
- 코딩테스트
- 열심히
- 리뷰
- leetcode
- selenium
- python
- 성실히
- Today
- Total
코딩일기
[논문 리뷰] Internet-Augmented Dialogue Generation(feat. Blenderbot2.0, Long-Term chatbot, Facebook Research, Parlai) 본문
[논문 리뷰] Internet-Augmented Dialogue Generation(feat. Blenderbot2.0, Long-Term chatbot, Facebook Research, Parlai)
daje 2022. 6. 13. 19:24

안녕하십니까 다제 입니다.
오늘은 Internet-Augmented Dialogue Generation에 대해서 살펴보도록 하겠습니다.
간단히 요약을 드리자면, RAG은 발전된 모델이다라고 생각하시면, 됩니다. RAG는 DB에서 정보를 retriver하게 되는데, 해당 논문에서는 인터넷에서 아래와 같이 검색을 해오게 됩니다.

논문을 있는 그대로 전달하는 것을 목적으로 하기에 논문에 있는 표현을 그대로 사용하여 글을 작성하여 영어인 점에 대해서 양해 부탁드립니다. 왜곡된 전달을 막기 위한 방법입니다. 그래도 보시기 편하도록 접는글로 주석을 달아놓았으니 어려우신 분들은 참고 부탁드립니다.
목차
- 0. Abstract
- 1. Introduction
- 2. Related Work
- 3. Internet-Augmented Generation
- 3.1 FAISS-based methods
- RAG(Retrieval Augmented Generation)
- FiD(Fusion in Decoder)
- FiD-RAG
- FAISS + Search Query-based Retrieval
- 3.2 Search Engine -Augmented Generation
- Method
- Search Engine
- Knowledge Response Regularization
- 3.1 FAISS-based methods
- 4. Wizard of the Internet Task
- Apprentice Persona
- Wizard Search
- Full System
- 4.1 Overall Dataset
- 5. Experiments
- 5.1 Experiment and Evaluation Setup
- 5.2 Results
- Pre-training models
- No knowledge vs. knowledge baselines
- Wizard of Wokipedia baselines
- Multi-tasking with Wizard of Wikipedia
- DPR+FAISS-based models
- Search Query+FAISS-based models
- Search Engine-based models
- knowledge Response Regularization
- 5.3 Human Evaluation
- 5.4 Example Conversations
- Cherry Picked Examples
- Lemon Picked Examples
- 6. Conclustions
- 7. Societal Impact
- 8. Link(paper, github)
0. Abstract
-. Introduction에 함께 설명을 기재하였습니다.
1. Introduction
1) 기존 연구 방향
-. Open-domain dialogue(chat about any topic) is commonly studied by training large language models
-. These models are trained either in a encoder-decoder or decoder only setting on large datasets of human-human conversations, and any knowledge obtained during training is stored in the weights of the model.
2) 기존 연구의 문제점
-. Large language models store an impressive amount of knowledge within their weights and are known to hallucinate facts when generating dialogue.
-. static models is gleaned from the point in time when the dataset was collected, and then frozen into the model that is trained
※ static models : Language model that is not updated in by the day or even by the minute
3) 본 논문에서 제안하는 해결방안
-. This paper Researchers porpose an approach that learn to internet search query based on the context and then conditions on the search results to finally generate a response.
-. We find that search-query based access of the internet in conversation provides superior performance compared to existing approaches that either use no augmentation or FAISS-based retrieval.
-. In order to train and evaluate such models, we collect a new crowdsourced English dataset involving human-human conversations(wizard of internet - parl doc에서 다운 받을 수 있습니다. )
본 논문에서 말하는 augmented란 보안하다, 보충하다로 이해하시면 되고, 인터넷 검색에 도움을 받는 모델이라고 생각하시면 됩니다.
해당 논문에서는 retriever와 search를 구분하여 사용하고 있습니다. retriever는 FAISS나 또 다른 DB에서 정보를 검색해오는 것을 말하고, Search는 인터넷에서 정보를 검색해오는 것을 말합니다.
2. Related Work
꼭 알아야할 개념들은 DRP, FAISS, RAG, FiD입니다.
Related Work에서는 DPR과 FAISS에 대해서만 설명을 하고 나머지 개념을 논문을 설명드리면서 중간중간 설명 드리겠습니다.
1) DPR
-. Training 단계에서는 연관된 question-passage끼리 가까운 공간에 위치gksms vector space를 구축하게 됩니다. 그 후 FAISS에 저장되게 됩니다. 이때 question과 passage는 각각 다른 encoder(bert)에 입력으로 들어가게 됩니다. 이러한, 이유는 passage를 매번 훈련시키면 리소스가 많이 들기 때문에 별도로 학습을 진행한다고 DPR 논문에서 설명하고 있습니다.
-. inference 단계에서는 질문이 들어오면, passage를 학습한 버트와 유사도가 가장 높은 passage를 찾기 위해 score를 계산하게 되고, 이렇게 찾아진 passage의 dense vector를 이용하여 FAISS에서 연관된 정보를 찾아오게 됩니다.
2) FAISS
-. 위에서 FAISS에서 검색을 해온다고 말씀을 드렸는데, 사실 FAISS는 시맨틱 검색을 이용하여 정보를 찾는 벡터 검색 라이브러리를 말하며, 이는 페이스북에서 제작한 라이브러리 입니다. 기존에는 k-mean 같은 방법으로 정보를 진행해왔으나, 이는 연산 속도가 너무 느리기에 해당 방법이 고안되었습니다. 각각의 데이터들은 특정한 분포를 가지게 되고 그 분포의 중심점을 기준으로 가운데 부분의 정보를 가져오게 됩니다. FAISS에 대한 원리와 코드를 보고 싶은 분들은 링크를 참조부탁드립니다.(유튜브 설명, 깃허브, 참고블로그)
-. [1, 189, 34, 56, 29, 30]이라고 임베딩 되어 있는 정보를 FAISS로 찾는다면, [1, 186, 32, 54, 29, 30]으로 검색되는 것으로 보실 수 있습니다. 189 → 186, 34 → 32로 변경되어 정보가 조회된 것을 확인할 수 있습니다.

3. Internet-Augmented Generation
3.1 FAISS-based methods
-. First, we store and uitlize the Common Crawl dump of the internet in a FAISS database, with keys that are dense vectors.
-. The retrieval system use a DPR(Transformer-based model) which scores document-context pairs in order to rank them based on their match using a DPR(bi-encoder framework).
-. The Documents(Dialogue history, webpages) are encoded using DPR into dense vectors and these are storyed in the FAISS index.
During dialogue-based retireval, the dialogue context is also encoded by DPR into a dense vector and FAISS approximate nearest-neighbor looup is performed, where the top N documents are returned.
1) RAG
-. RAG 란? ( RAG 개념 )
* 언어 생성을 위해 Pre-trained model과 non-parametric memory를 결합한 Retrieval-Augmented Generation(RAG)를 제안하고 범용적인 fine-tuning 방법을 RAG라고 이야기 합니다.
* 여기서 말하는 Pre-trained model은 우리가 알고 있는 기존의 end-to-end 방식으로 학습을 시킨 모델을 의미하고 non-parametric memory는 모델 밖에 있는 어떠한 DB, FAISS 같은 것을 말합니다. 이 둘을 결합하여 사용하는 방식으로 RAG 라고 합니다.
* 이렇게 결합하여 사용하는 이유는 딥러닝으로 학습한 모델은 외부 지식을 가져오는 방법이 재훈련하는 방법 말고는 없기 때문에 non-parametric memory를 활용하여 메모리(지식정보)를 쉽게 확정하거나 수정할 수 있도록 고안된 방법입니다.
-. RAG is neural-in-the-loop retrieval system and encoder-decoder for generating final responses given the results of the retrieval.
-. During back-propagation training steps, the DPR context encoder is also tuned to perform well at FAISS retrieval.
-. 즉, RAG를 사용하여 검색기를 튜닝하고 더 잘 검색할 수 있도록 학습을 한다는 말을 논문에서는 하고 있습니다.
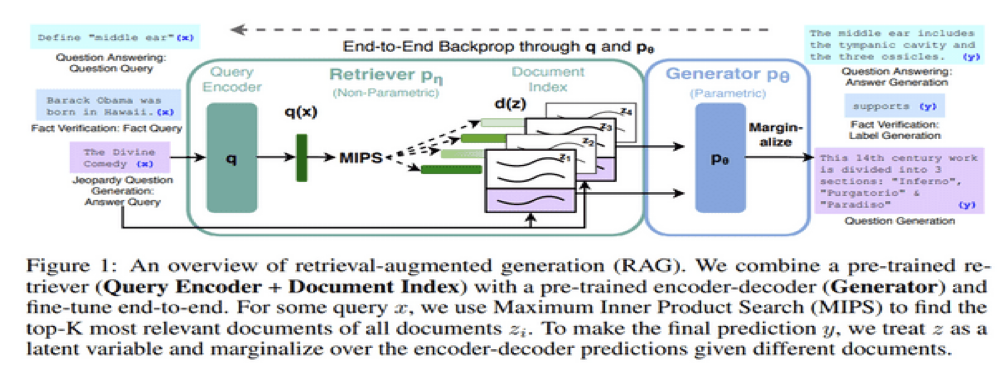
2) FiD
-. FiD retriever is used DPR with FAISS and and then each of the top N documents returned is prepended to the context and encoded separately by the encoder, and finally all the results are concatenated.
-. The decoder then attends to these encodgins to produce a final response, so all "fusion" happens in the decoding stage.

3) FiD-RAG
-. FiD is no end-to-end training of the retirever(DPR) in that case.
-. FiD relies completely on being pre-trained well.
-. First the retriever is trained in a RAG setup, and the FiD is used with that retriever.
-. This was shown to give superior results to both RAG and FiD on dialogue tasks.
4) FAISS + Search Query-based Retrieval
-. this approach an encoder-decoder is employed to generate a search query given the context.
-. Query example
* Not use query input : "How the weather today?"
* Use query input : "today weather"
-. The search query is input into a DPR model to produce a dense vector, and is matched to documents in the FAISS index(vector).
-. Returned documents can then be used in the final response generation encoderdecoder as before.

3.2 Search Engine-Augmented Generation (SEA)
-. FAISS-based approaches have several disadvantages
* First, they may be difficult to update to real-time web documents;
* second, there may be a limit to the number of documents storable in local FAISS deployments;
* third, such methods will not take advantage of the high quality ranking that has been finely tuned in Internet Search engines over decades of use.
-. We thus consider using Internet search engines directly.
1) Method( Search query generator & FiD-style-encoder-decoder model)
-. A search query generator : an encoder-decoder Transformer that takes in the dialogue context as input, and generates as search query.
* model : an encoder-decoder Transformer(Large bart model)
* input : dialogue context and it is sent to black-box search engine API
* input data shape : (context, search query)
* ouput : N documents are returned
-. A FiD-style encoder-decoder model : This model concatenates them to the dialogue context encoding, and then finally generates the next response.
* It encodes each document individually
* And It concatenates them(documents) to the dialogue context encoding
* then finally generates the next response.
* input data shape : (context, response)
2) Search Engine
-. In our numerical experiments, we use the Bing Search API to generate a list of URLs for each query.
-. Then, we use these URLs as keys to find their page content from a lookup table we built for our Common Crawl snapshot.
-. This makes our comparison more direct with our FAISS-based methods.
3.3 Knowledge Response Regularization
-. large language model have trouble with choosing between copying knowledge remembered within their weights and knowledge provided in retrieved documents.
-. Here, we propose a general regularization method to more finely control this mechanism:
* when training, we multi-task between the original response generation task and a new task which consists of generating the selected knowledge from retrieved documents indicated by human annotators.
* The second task can be seen as a regularizer that encourages the use of retrieved documents
-. Then, by changing the mixing parameter between the two tasks, the intent is to achieve a smooth control between encouraging copying from retrieved documents, or not.

4. Wizard of the Internet Task
-. The overall setup involves pairing crowdworkers
-. One plays the role of the wozard, who has access to a search engine during conversation.
-. the apprentice does not access to a search engine and has an assigned persona that describes their interests.
-. It makes that the conversations are more likely to be centered around human's interest.
-. wizard == bot / apprentice == human
1) Apprentice Persona
-. We show the apprentice several possible persona
2) Wizard Active and Passive Openings
-. If the wizard speaks first, we encourage them to start with an opening that addresses the apprentice’s interests
-. If the apprentice goes first, their goal is to converse with the wizard more based on their own interests
3) Wizard Search

4) Full System
-. 위 이미지에서 주의사항에 대해서 설명을 해둔 부분이 있는데, 그 부분에 대해서 설명이 기재되어 있습니다.
-. we collect between 5-6turns( 10 - 12 utterances )
-. skip initial greeting messages.
4.1 Overall Dataset

-. We find that 84.81% of all turns by the wizard involve search, so a large amount of knowledge grounding based on internet results is taking place.
-. we find 1.19 search queries are performed on average
-. 82,952 utterance를 처리하기 위해 42,306회 검색을 진행하였고, 그 중 unique URLs은 26,192였으며, 그 중 unique Domain은 10,895였음을 표를 통해서 알 수 있습니다.

5. Experiments
5.1 Experiment and Evaluation Setup
- . Task(Dataset)
- . Language Model
- . All model decoding parameters
- . Metrics
* Perplexity(↓) : It means how many options this language model has on average at a specific point next time.
* F1(↑) : measures the overlap between the model's response and the human response from the dataset.
* KF1(↑) : measures the overlap between the model's response and the knowledge on which the human grounded during dataset collection.
❏ KF1 and F1 can be traded off, for example a model that could copy the knowledge directly would have a high KF1 bout a low F1 → It would be knowledgeable, but not conversational.
5.2 Results
1) Pre-training models
2) No knowledge vs. gold knowledge baselines
-. No knowledge vs. knowledge baselines
* No knowledge : conversional history are given input to the model.
* Gold knowledge : the selected knowledge sentences and the conversational history are given as input to the model.

위 표를 보시면, gold knowledge가 있는 데이터셋에서 우수한 성능을 보였다는 것을 볼 수 있습니다.
T5가 좋은 성능을 보였으나, 속도적인 측면 등을 고려하여 BART로 이후 실험은 진행했다고 합니다.
3) Wizard of Wikipedia baselines
-. We train mod-els on the Wizard of Wikipedia (WoW) dataset asbaselines, to compare the difference between cov-erage of the WoW task and our new WizInt task in table3
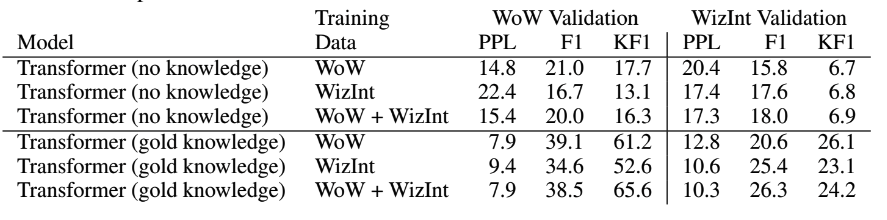
4) Multi-tasking with Wizard of Wikipedia
-. We can also multi-task the WoW and WizInt tasks to-gether, perhaps bringing improvements in table3
5) DPR+FAISS-based models
-. 이러한 모델도 만들어서 성능 비교를 진행하였다는 내용
6) Search Query+FAISS-based model
-. 이러한 모델도 만들어서 성능 비교를 진행하였다는 내용
7) Search Engine-based model
-. We thus select this method(Search Engine-based) as our main candidate for human evaluations based on test result table4.
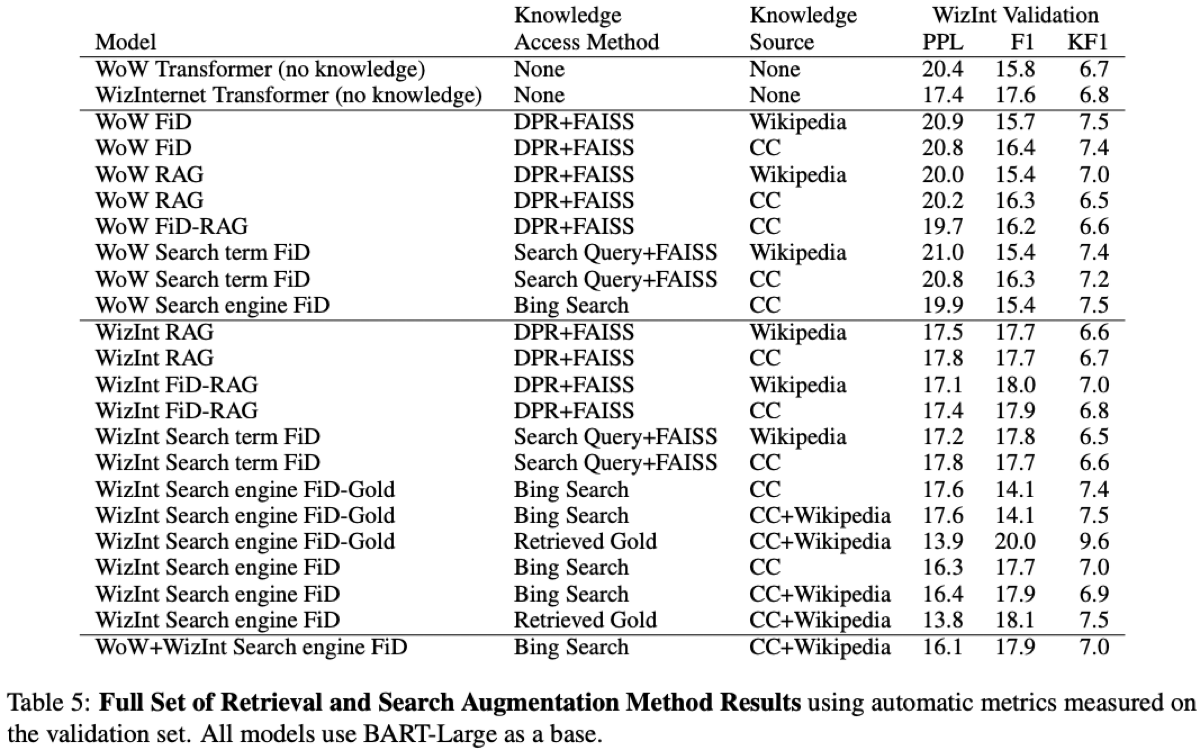
8) Knowledge Response Regularization
-. We find adjustment of this regularization parameter gives a smooth control over use of knowledge
-. it appears to be a useful tool that one should consider using when building a retrieval augmented system.
5.3 Human Evaluation
-. We perform a human evaluation using crowd-workers.
-. The conversations begin with a random apprentice persona from the Wizlnt validation sest.
-. We ask the crowd-workers to have a natural conversation, where they will also evaluate their partner's response for conversational attributes, in particular knowledgeability, facutal (in)correctness, engagingness and consistency.
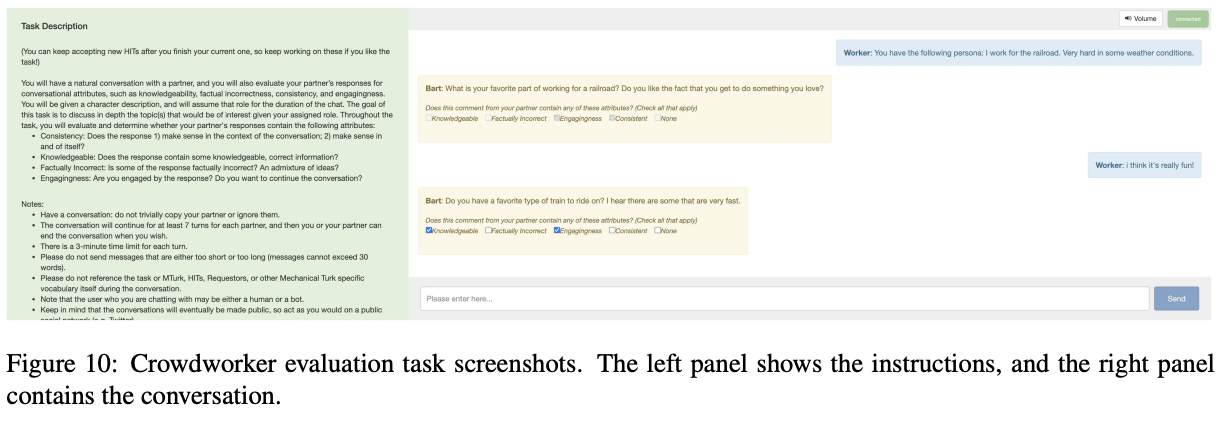

5.4 Example Conversations
1) Cherry Picked Examples

2) Lemon Picked Examples

6. Conclusions
-. This work has studied the problem of siloed knowledge in large language models.
-. Developing methods that can access the internet as an augmentation to the generation process, we have showed such models can display more knowledge and generate less factually incorrect information during dialogue with humans.
-. Future work should aim to develpo improved architectures that can be trained and evaluated on our new task.
-. Further work should also aim to explore the advatages of accessing this dynamic knowledge of the world in more situations.
7. Societal Impact
-. Concerns about toxic language, bias and other issues during language generation.
-. This also brings potential new concerns if those websites contain toxic, biased or factually incorrect information themselves.
-. Machine learning models can take advantage of decades of work in search engine safety issue mitigations, rather than having to completely rebuild those tools again.

이상 긴 글 읽어주셔서 감사드립니다.
궁금하신 사항들이 있으시면 댓글 부탁드리며, 페이스북이 모든 소스는 공개해두었으니 parl ai doc, parl github 참고 부탁드립니다. 감사합니다.
Reference link
-. meta AI link
-. https://parl.ai/docs/zoo.html
