
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- pandas
- 부트캠프
- 주간보고
- SQL
- 2021
- 자료구조
- 딥러닝
- 재미져
- 리뷰
- 선형회귀
- 빅데이터
- Ai
- 기초통계
- 코딩테스트
- selenium
- 매일매일
- leetcode
- 열심히
- JavaScript
- python
- 코드스테이츠
- Codestates
- 독서
- 노마드코더
- 꾸준히
- MYSQL
- 파이썬
- bootcamp
- yolo
- 성실히
- Today
- Total
코딩일기
배치 정규화(Batch Normalization) 본문
안녕하십니까 다제입니다.
오늘은 배치 정규화에 대해서 살펴보도록 하겠습니다.
배치 정규화는 기울기 소실(Gradient Vainshing)과 폭주(Exploding)을 극복하기 위한 하나의 방안으로 사용됩니다.
이 외에도 가중치 초기화(Weight Initializaion), 층정규화(layer Normaliztion) 등으로 기울기 소실과 폭주를 최소화 할 수 있습니다.
혹시 몰라서 말씀드리면, 딥러닝에서 역전파하는 과정에서 기울기 소실과 폭주가 일어나면, 해당 부분은 학습이 원활히 이루어지지 않는 경향을 보이기 때문에 주의가 필요합니다.
그럼 배치 정규화는 무엇인가? 어느 타이임에 넣어야하고, 어떤 종류를 우리가 제작하는 모델에게 적용을 해야할까요?
하나씩 찬찬히 알아보도록 하겠습니다. 아! 해당 포스팅은 위키독스, 나동빈 유트버, 핸즈온 머신러닝(2판)에서 학습한 내용을 종합하여 포스팅을 진행하였습니다.
배치 정규화 정의
인공 신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화하여 학습을 효율적으로 만듭니다.
배치 정규화를 하는 이유
딥러닝에서 층에서 층으로 이동될 때마다 이전 층들의 학습에 의해 가중치 값이 바뀌게 되면, 현재 층에 전달되는 입력 데이터의 분포와 현재 층에 학습했던 시점의 분포와 차이가 발생합니다. 이러헤 층 별로 입력 데이터 분포가 달라지는 현상을 "내부 공변량 변화"이라고 합니다.
※ 공변량 변화 vs 내부 공변량 변화
-. 공변량 변화 : 훈련 데이터의 분포와 테스트 데이터의 분포가 다른 경우를 의미
-. 내부 공변량 변화 : 신경망 층 사이에서 발생하는 입력 데이터의 분포 변화를 의미
배치 정규화가 이루어지는 시점
각 층에서 활성화 함수를 통과하기 전에 수행
배치 정규화의 장점
- 훨씬 큰 학습률을 사용할 수 있어 학습 속도를 개선시킵니다.
- 배치 정규화를 사용하면 시그모이드 함수나 하이퍼볼릭탄젠트 함수를 사용하더라도 기울기 소실 문제가 크게 개선됩니다.
- 가중치 초기화에 훨씬 덜 민감해집니다.
- 미니 배치마다 평균과 표준편차를 계산하여 사용하므로 훈련 데이터에 일종의 잡음 주입의 부수 효과로 과적합을 방지하는 효과도 냅니다. 다시 말해, 마치 드롭아웃과 비슷한 효과를 냅니다. 물론, 드롭 아웃과 함께 사용하는 것이 좋습니다.
- 배치 정규화는 모델을 복잡하게 하며, 추가 계산을 하는 것이므로 테스트 데이터에 대한 예측 시에 실행 시간이 느려집니다. 그래서 서비스 속도를 고려하는 관점에서는 배치 정규화가 꼭 필요한지 고민이 필요합니다.
- 배치 정규화의 효과는 굉장하지만 내부 공변량 변화때문은 아니라는 논문도 있습니다.
배치 정규화의 한계
1. 미니 배치 크기에 의존적이다.
배치 정규화는 너무 작은 배치 크기에서는 잘 동작하지 않을 수 있습니다. 단적으로 배치 크기를 1로 하게되면 분산은 0이 됩니다. 작은 미니 배치에서는 배치 정규화의 효과가 극단적으로 작용되어 훈련에 악영향을 줄 수 있습니다. 배치 정규화를 적용할때는 작은 미니 배치보다는 크기가 어느정도 되는 미니 배치에서 하는 것이 좋습니다. 이처럼 배치 정규화는 배치 크기에 의존적인 면이 있습니다.
2. RNN에 적용하기 어렵다.
뒤에서 배우겠지만, RNN은 각 시점(time step)마다 다른 통계치를 가집니다. 이는 RNN에 배치 정규화를 적용하는 것을 어렵게 만듭니다. RNN에서 배치 정규화를 적용하기 위한 몇 가지 논문이 제시되어 있지만, 여기서는 이를 소개하는 대신 배치 크기에도 의존적이지 않으며, RNN에도 적용하는 것이 수월한 층 정규화(layer normalization)라는 방법을 소개하고자 합니다.
입력정규화의 목적 : 하나의 데이터가 각각의 축에 대해서 비슷한 범위를 가지게 하는 것이 목표
입력데이터가 표준 정규분포의 값을 가질 수 있도록 값을 변경하는 것이 목표이다
Input : 미니 배치 B={x(1),x(2),...,x(m)}
Output : y(i)=BNγ,β(x(i))
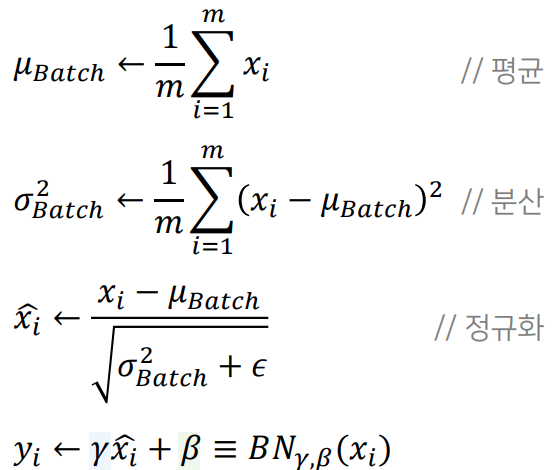
- m은 미니 배치에 있는 샘플의 수
- μB는 미니 배치 B에 대한 평균.
- σB는 미니 배치 B에 대한 표준편차.
- x^(i)은 평균이 0이고 정규화 된 입력 데이터.
- ε은 σ2가 0일 때, 분모가 0이 되는 것을 막는 작은 양수. 보편적으로 10−5
- γ는 정규화 된 데이터에 대한 스케일 매개변수로 학습 대상
- β는 정규화 된 데이터에 대한 시프트 매개변수로 학습 대상
- y(i)는 스케일과 시프트를 통해 조정한 BN의 최종 결과
'Code > 딥러닝(NL)' 카테고리의 다른 글
| [NLP] 1. Text Preprocessing(feat. Tokenization, Cleaning, Normalization, Stopwords, Building Vocab, Integer Encoding, Padding, Vectorization, 텍스트 전처리 과정) (0) | 2022.02.13 |
|---|---|
| GPT1 (0) | 2021.12.20 |
| Deeping Weight Update와 Batch, Batch_size의 관계 (0) | 2021.10.22 |
| Categorical_crossentropy? Sparse_categorical_crossentropy? (0) | 2021.10.21 |
| [numpy] np.newaxis는 무엇이고 언제 사용하는가? (0) | 2021.10.04 |


